The project page says,
Tourist is a new approach to documentation that allows programmers to explain low-level technical details of a system while simultaneously providing the context of how those details fit into the broader architecture. It lets programmers document code in the same way that they would explain it in person: by walking the consumer step-by-step through the important parts of a codebase.
That’s really all Tourist is – a tool (currently an extension for Visual Studio Code) that allows programmers to guide virtual “tours” of their code. Rather than writing technical documentation in a wiki or other format that is totally external to the code, Tourist lets you associate documentation with specific locations in the code, and then makes it easy to view that documentation in the appropriate context.
What is a tour?
A tour is a series of code locations (a particular line in a particular file) along with a markdown description of why that location is significant. The locations (or “stops”) can be in different files and even in different git repositories.1
Tourist provides a simple interface for building and viewing tours. The GIF below shows what it’s like to view a tour in Visual Studio Code.
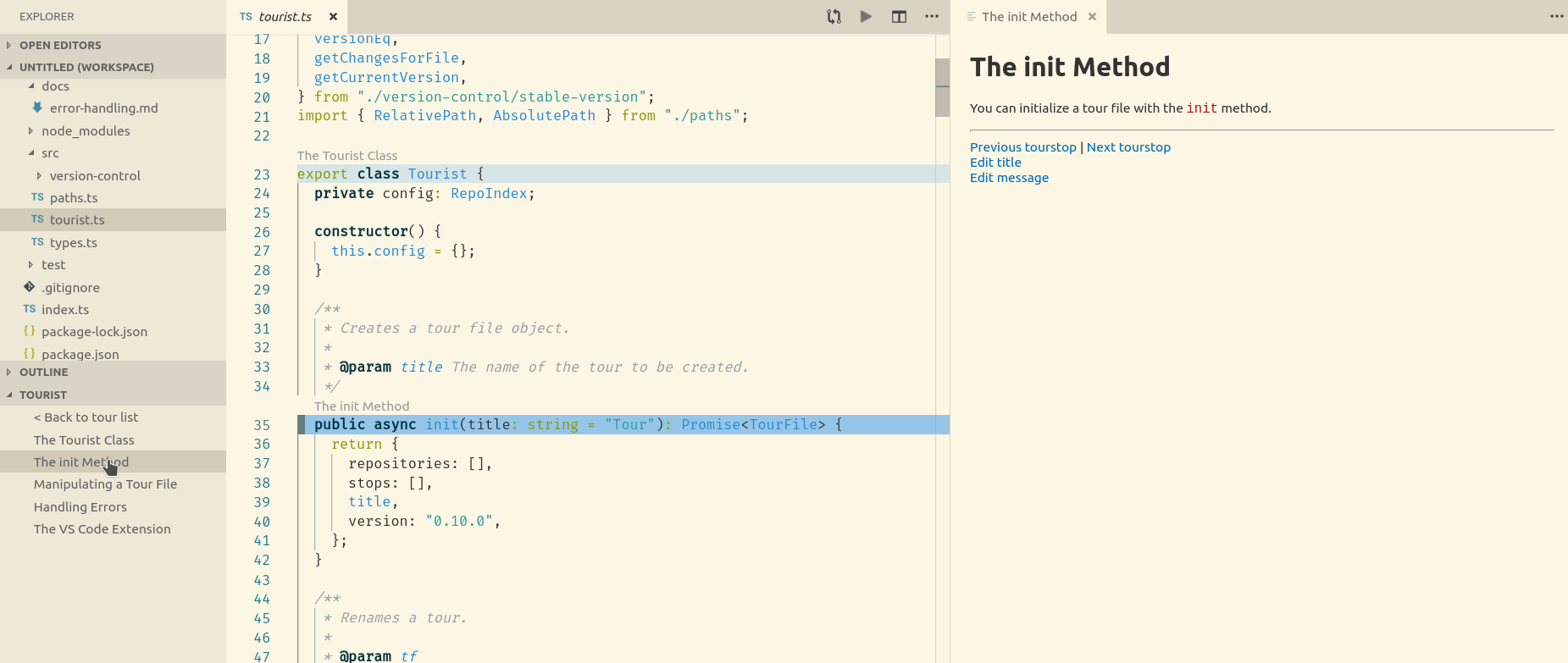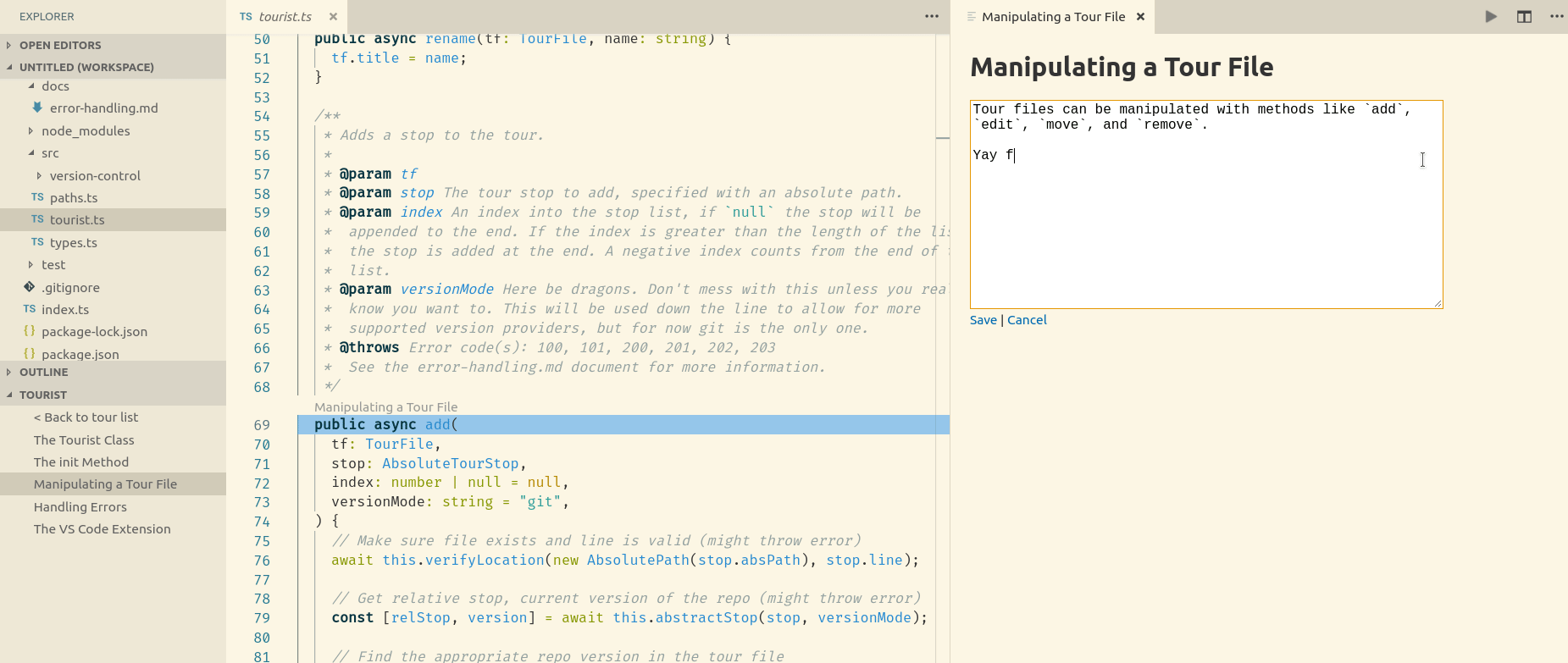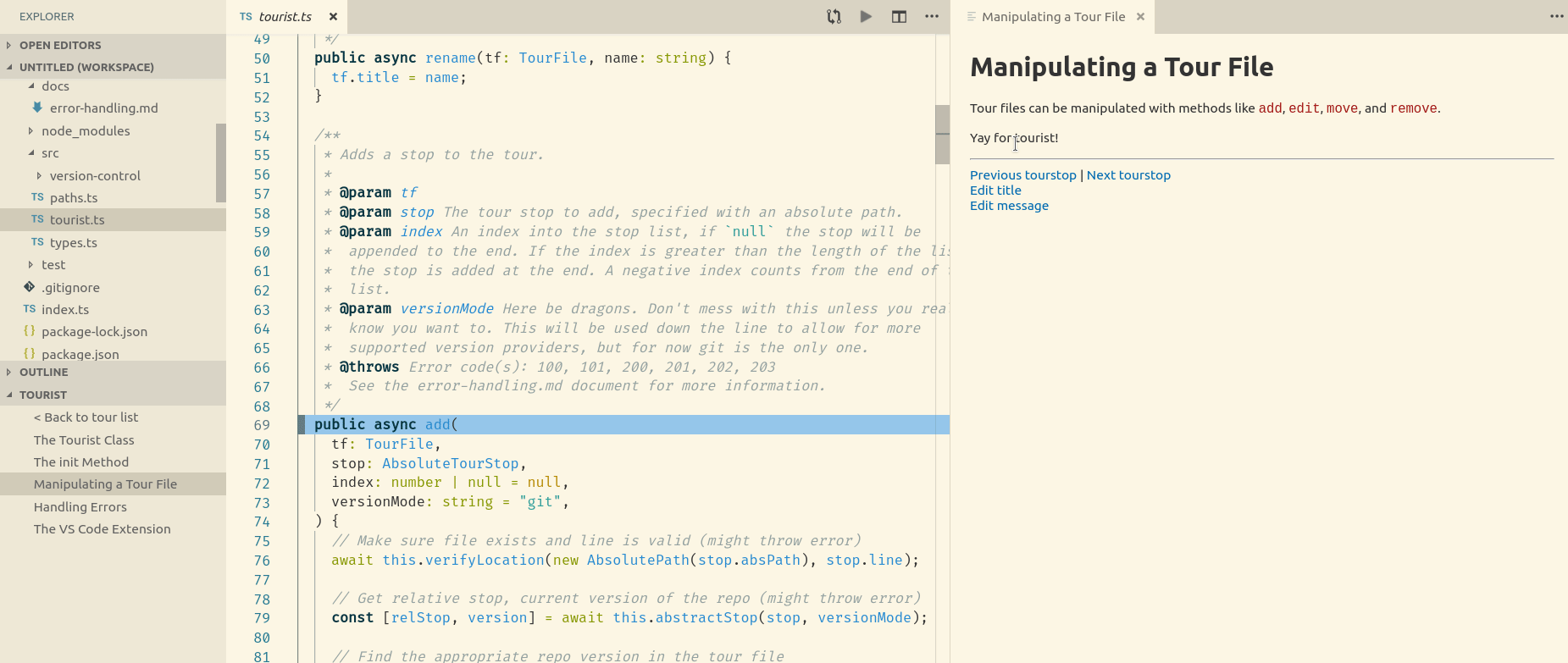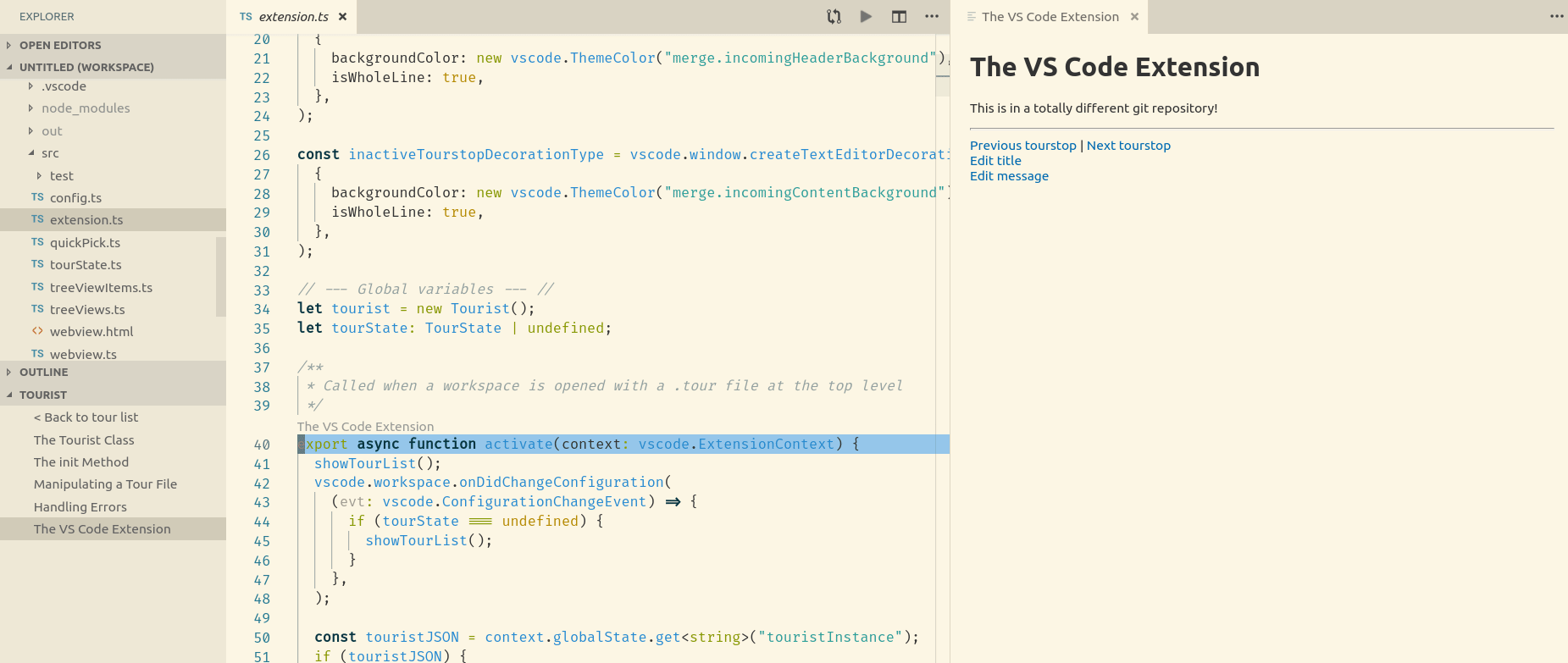
When you click on a tour stop, your editor jumps to the appropriate file and line, and the stop’s markdown content is rendered in a “web-view”.
Adding tour stops is as easy as viewing them. Once you have a tour file created, you can simply right click in a file and ask tourist to add a stop at that location. From there you can edit the stop content, move the stop around, and reorder stops as needed.
(This demo is fairly simple, and the first version of the extension is planned to stay that way. That being said, we have lots of cool ideas for how the extension can be made more powerful in the future, and we welcome suggestions.)
Why is this exciting?
As I mentioned before, long-form external documentation like wiki pages is disconnected from the code that it documents. A technical report can explain a lot about class X or function Y, but you have to do your own legwork to actually connect that information to the logic involved. In addition, it is really easy to forget to maintain the documentation as the code changes. If class X becomes class Z you need to change that in your documentation too, and that documentation generally fairly far-removed from the place that you made the change.
Inline comments have a different issue: context. When you read inline comments, you’re generally only reading to understand a particular line or set of lines. Maybe a docstring on a module or function gives you sligtly more context, but the main goal is still to explain the code that’s written right here. When inline comments to try to explain broader context, it can start to get hard to read the actual code. Tourist’s idea of documentation that is connected to a code location but not written inline is an attractive solution to this problem.
Of course, both inline comments and long-form documentation are important, and Tourist doesn’t necessarily intend to replace either. Long-form documentation is still crucial for less technical documentation like user manuals, as well as for more external techncial things like release notes. Inline comments provide important insight into the nitty-gritty details of an algorithm. Code tours bridge the gap between these worlds, rounding out a project’s documentation by addressing the interaction between high-level architectural concerns and low-level information about the code itself.
What can I use it for?
This technology is still really new, and we expect that people will come up with all sorts of interesting ways to use it. That being said, here are a few things that I think tours are really good for:
- Onboarding. Getting started with a new codebase is always a challenge, and it’s often really helpful to have someone who already knows the code walk you through the important parts. Tourist provides a low-cost, repeatable method of knowledge transfer. This is especially powerful when someone is leaving a company or project and needs a quick way to write down as much knowledge as possible. Someone can come along later and pick up the project as if the old maintainer was still there.
- Low-level demos. When demoing a new feature or code-path to other programmers, it is often helpful to show how data flows through the new code. A code tour that hits each important branch point in turn makes it really easy to see the impact of the change.
- Library overviews. Automatically generated documentation isn’t always enough information for someone to use a library effectively. Library writers can use Tourist to put use-case code snippets alongside the actual code that is being called in the snippets.
If you have other ideas, reach out and let me know! I’m really excited to see what we can do with this framework.
How can I get it?
Tourist is in extremely early alpha, so you’ll need to build everything
yourself. First and foremost, you’ll need tourist from
hgoldstein95/tourist, and unless
you’re going to write your own editor extension, you’ll want tourist-vscode
at
hgoldstein95/tourist-vscode.
Getting tourist set up should be fairly straightforward – the README
should have enough information. Once that’s built, you can run
npm install
from tourist-vscode and start the extension with the debugger.
If you’re trying to get tourist up and running on your machine, feel free to send me an email or create an issue on either of the above repositories. I’m happy to help anyone who wants to help us keep moving tourist forward.
Watch this blog for more about tourist! As we move towards a feature-complete launch, I’ll keep this page updated, and I’ll probably post again with news and information.
-
As of now, Tourist requires that all of the code you reference is versioned using git. In the future we hope to add support for subversion and mercurial, but git is universal enough that we think this is the right place to start. ↩




